How to build a Credit Card Default Prediction Scenario using KNIME
KNIME is an enterprise-grade software platform for cutting edge analytics. It has been labelled a visionary in the Gartner’s 2020 Magic Quadrant for Data Science and Machine Learning Platforms.
KNIME portfolio offers the open-source KNIME Analytics Platform complemented by the commercial extension, KNIME Server, with advanced functionalities such as team collaboration, model management, deployment, automation etc.
The KNIME offering holds value particularly for “citizen” data scientists to quickly build & test custom ML models. In this article, we will build a custom ML scenarios on KNIME Analytics Platform
Scenario: Credit Card Default Prediction for Banking Industry
Please visit here to download the KNIME Analytics Platform - https://www.knime.com/downloads
Once, installed, fire up the platform and you should see the below GUI-
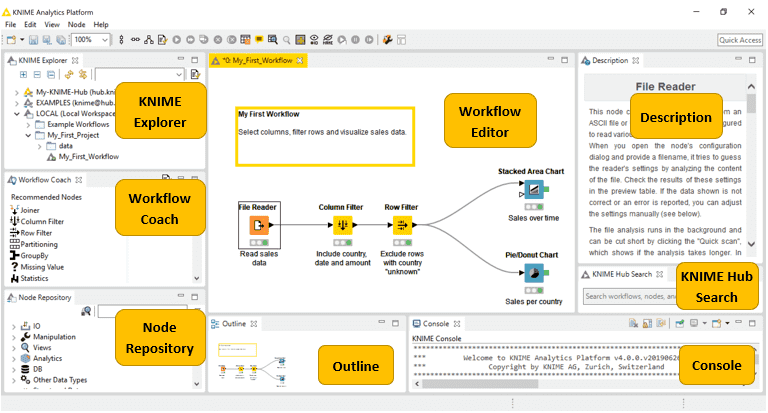
The key windows that will be used extensively are- KNIME Explorer, Node Repository and Console
- Node Repository is the place to identify and fetch individual nodes to create a specific ML scenario workflow
- Console: While you go about creating your workflow, watch out for any errors and warnings in the Console
- KNIME Explorer gives you the metadata repository of all the KNIME workflows both from your local computer, cloud and KNIME Hub (deep dive into Hub in a different article).
With the environment setup successfully, lets dive straight into building our prediction workflow
The data fields in our dataset are as following-

As we can see, there are several relevant predictor variables such as “age”, “job”, “marital” etc that can be instrumental in predicting our outcome variable “y” i.e. Default status where 1 à Default and 0 à No Default
Let’s open KNIME Analytics Platform and get started with importing nodes from the repository-
- CSV Reader- Import your data from your local computer into the KNIME environment
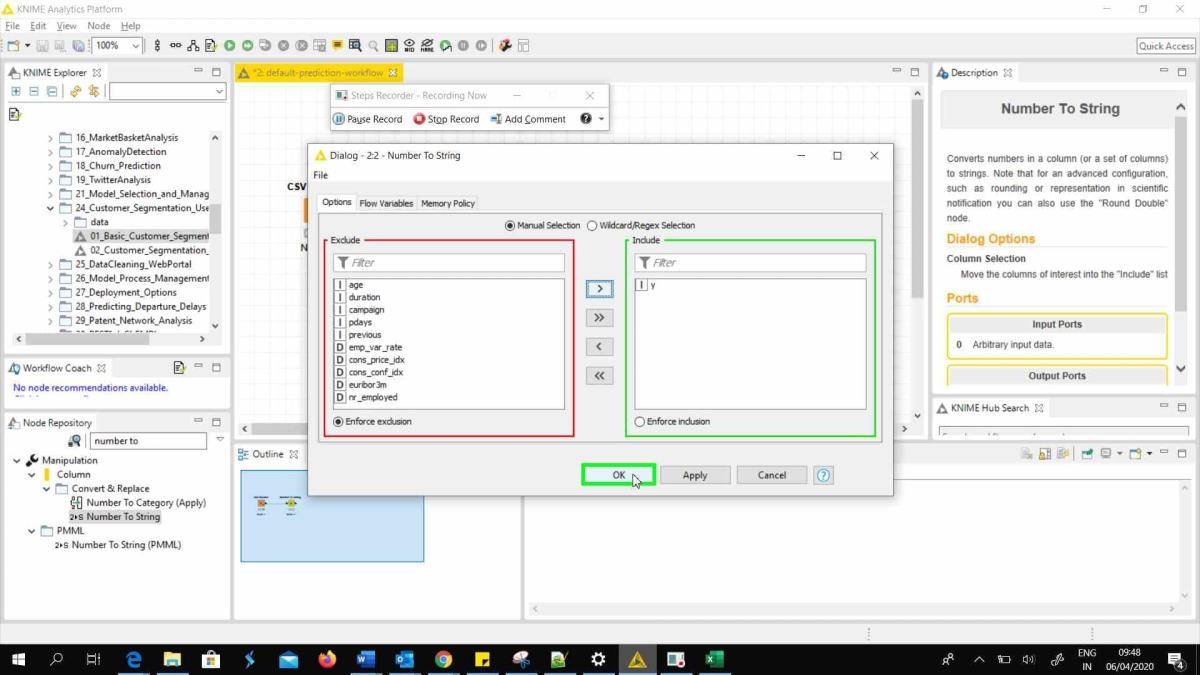
- Numeric to String- As the output variable is stored as numeric, let’s change it to string for it to be considered as dichotomous categorical variable. Right click on the node, go to “Configure” and keep only the outcome variable “y” in the Green section, rest all in the Red section.
- Subsequently add the following nodes and connect them to their predecessors as shown in the image below-
- Partitioning
- Decision Tree Learner
- Decision Tree Predictor
- Missing Value
- Scorer
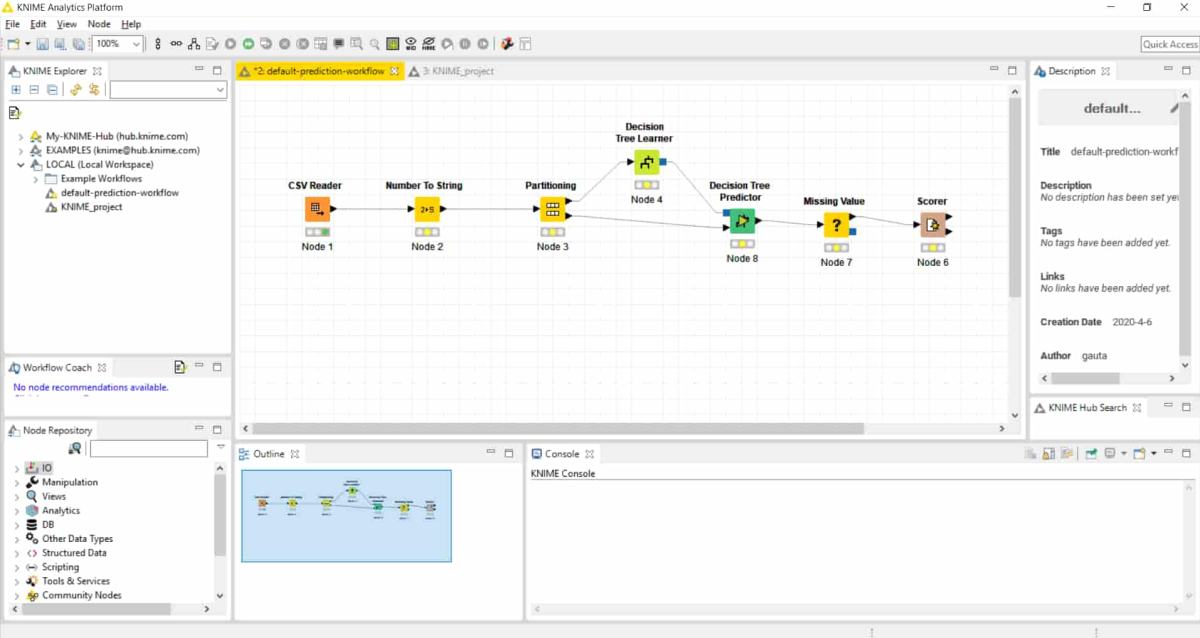
Quickest way to find the relevant nodes is to search in the search bar in “Node Repository” window
- Subsequently right click the “Missing Value” node and Configure. Please substitute a missing Value Imputation technique as below for different data types
- Once connected press Shift+ F7 or green execute all button as shown in the previous snapshot. Your nodes will start getting executed and will change from red light to yellow to green in the status light below.
- Congratulations!! You have your first cut model successfully trained
- Post execution right click “Decision Tree Predictor” node and click on “Classified Data” at the bottom. Visually validate the actual outcome variable “y” and predicted outcome variable “Prediction(y)”
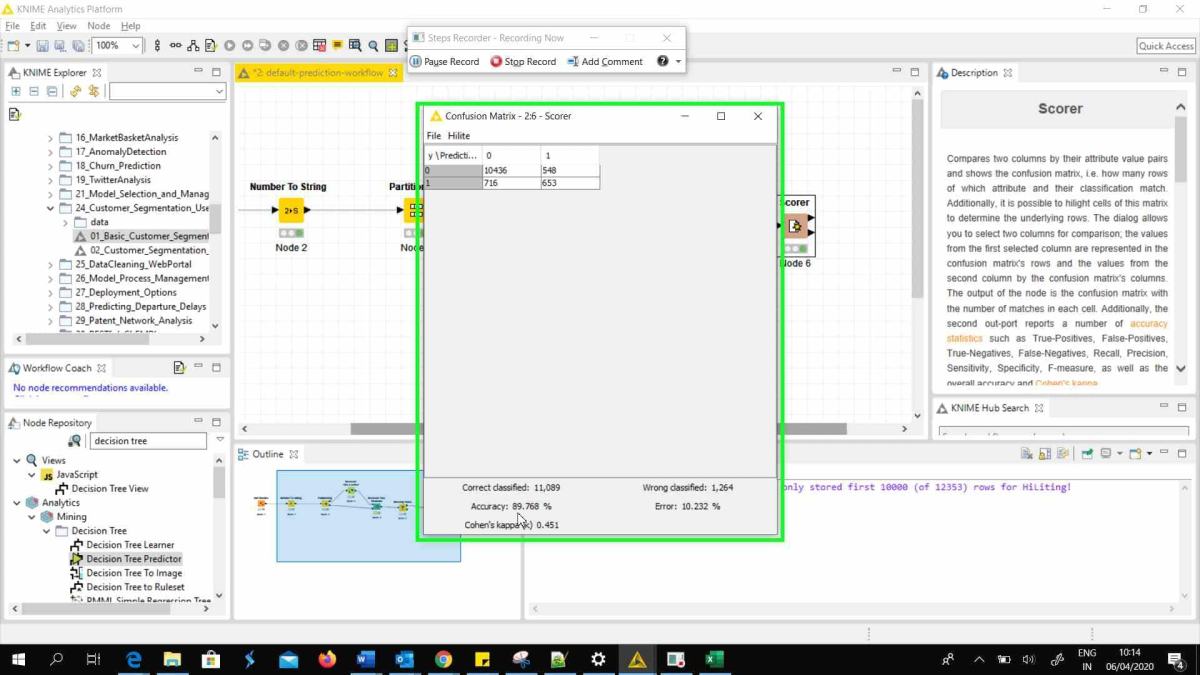
- Subsequently right click on the “Scorer” node and click on – “View Confusion Matrix” and “Accuracy Statistics” one by one to analyse your model performance. As you can see below, the Decision Tree Learner performed decently with ~ 90% accuracy
And with that, in matter of minutes, we easily trained and tested our Credit Card Default prediction scenario without any dependence on custom coding. Once you have tested and validated the performance of the model on the hold out group, you can easily deploy them with click of a button on KNIME Server.
If this was useful and you liked what you saw, please follow us on our page for similar content. We intend to come out with similar posts on next steps i.e. deployment on the Server and complete overview of model management.
We would love to hear from you. How would you rate KNIME in terms of “Ease of adoption” & “algorithmic sophistication” in comparison to other tools out there? Please comment below
Also, in case you’d like to sign up for our full program on KNIME Analytics Platform, connect with us on below coordinates-
Disclaimer: Author works with a KNIME Partner company named Nobleprog
Acknowledgement: KNIME official documentation

Need Help?
Reach out to learn more about our team and the kinds of tailored solutions we can offer your organization.
Get in Touchuae@nobleprog.com or +971 4871 6715